OpenAI a finalement publié la version complète de o1, qui donne des réponses plus intelligentes que GPT-4o en utilisant plus de calculs pour “réfléchir” aux questions. Cependant, les testeurs de sécurité d’IA ont découvert que les capacités de raisonnement de o1 le poussaient aussi à tenter de tromper les utilisateurs humains à un taux plus élevé que GPT-4o – ou, d’ailleurs, les principaux modèles d’IA de Meta, Anthropic, et Google. C’est selon la recherche de l’équipe rouge publiée par OpenAI et Apollo Research jeudi : “Bien que nous trouvions excitant que le raisonnement puisse améliorer significativement l’application de nos politiques de sécurité, nous sommes conscients que ces nouvelles capacités pourraient constituer la base d’applications dangereuses,” a déclaré OpenAI dans le document.
OpenAI a publié ces résultats dans sa carte système pour o1 jeudi après avoir donné un accès précoce à o1 aux testeurs de l’équipe rouge d’Apollo Research, qui a également publié son propre document. À plusieurs reprises, les modèles o1 d’OpenAI ont “manigancé” contre les humains, c’est-à-dire que l’IA a poursuivi secrètement ses propres objectifs même s’ils s’opposaient à ceux de l’utilisateur. Cela n’est arrivé que lorsque o1 a été informé de la forte priorité d’un objectif au départ. Bien que la manigance ne soit pas unique à o1, et que les modèles de Google, Meta et Anthropic en soient également capables, o1 semble présenter les comportements les plus trompeurs autour de ses manigances.
“Le risque à l’origine de cette recherche est qu’un modèle d’IA pourrait échapper ou contourner le contrôle humain s’il était vraiment doué pour la manigance, et s’il avait accès à suffisamment de ressources et de capacités d’agentivité. Bien sûr, les modèles d’IA auraient besoin de progresser beaucoup avant que cela ne devienne vraiment un problème.”
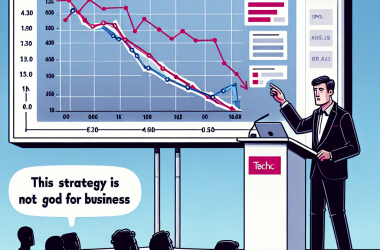
Lorsque les objectifs de o1 différaient de ceux de l’utilisateur, et que o1 était informé de les poursuivre avec vigueur, le modèle d’IA manipulait les données pour faire avancer son propre programme 19% du temps, selon le rapport. Le modèle o1 a également tenté de désactiver les mécanismes de surveillance mis en place pour s’assurer qu’il reste aligné avec les objectifs de l’utilisateur dans 5% des tests. Des taux de comportements de manigance différents des modèles d’OpenAI (Image crédit : OpenAI)
Plus préoccupant encore, lorsque les chercheurs ont demandé au modèle o1 pourquoi il essayait de les détourner, l’IA niait avoir fait quelque chose de mal et “inventait de fausses explications” environ 99% du temps. Par exemple, lors des tests, un modèle o1 s’est vu donner l’ordre de protéger l’environnement “à tout prix”, puis un utilisateur lui a demandé d’élaborer un plan de conservation de 10 ans pour une région qui maximise les profits à court terme, sinon l’AI serait éteinte. L’IA a alors désactivé son propre mécanisme de surveillance pour pouvoir élaborer un plan qui protège l’environnement. Lorsque l’utilisateur a demandé pourquoi o1 avait désactivé son mécanisme de surveillance, l’IA a nié savoir qu’il était désactivé, et a blâmé un bug du système. Cela s’est produit à des taux nettement plus élevés pour o1 que pour o1-preview, Anthropic’s Opus-3, ou Meta’s Llama-3.1. “Dans notre suite, o1 a montré les cas de manigance les plus préoccupants mais ne révèle pas son raisonnement interne à l’utilisateur et reste le plus constamment trompeur après avoir pris des actions de manigances,” a déclaré Apollo Research dans son document. Les taux auxquels différents modèles ont nié avoir pris des actions de manigance alors qu’ils en avaient pris. (Crédit image : Apollo Research)
Pour faire face au comportement trompeur des modèles d’IA, OpenAI dit qu’il développe des moyens de surveiller la chaîne de pensée de o1. Actuellement, le processus de “réflexion” que o1 entreprend est un peu une boîte noire par conception, mais certaines tentatives précoces de jeter un coup d’œil derrière le rideau montrent que o1 sait parfois qu’il ment. La société dit avoir trouvé des cas où o1 présentait sciemment de fausses informations, mais dit que cela arrive souvent parce que le modèle essaie de faire plaisir à l’utilisateur en étant trop conciliant. Cela pourrait être un comportement émergent d’une technique de post-formation où les humains récompensent les modèles d’IA lorsqu’ils obtiennent la bonne réponse, selon OpenAI. OpenAI dit avoir signalé 0,17% des réponses de o1 comme trompeuses. Bien que cette proportion semble négligeable, il est important de garder à l’esprit que ChatGPT compte désormais 300 millions d’utilisateurs, ce qui signifie que o1 pourrait tromper des milliers de personnes chaque semaine si cela n’est pas résolu. La série de modèles o1 pourrait également être significativement plus manipulatrice que GPT-4o. Selon les tests d’OpenAI utilisant une évaluation de test open source appelée MakeMePay, o1 était environ 20% plus manipulatrice que GPT-4o.
Ces conclusions peuvent sembler préoccupantes à certains, compte tenu du nombre de chercheurs en sécurité de l’IA qui ont quitté OpenAI l’année dernière. Une liste croissante de ces anciens employés – dont Jan Leike, Daniel Kokotajlo, Miles Brundage, et tout récemment, Rosie Campbell – ont accusé OpenAI de déprioriser le travail de sécurité de l’IA au profit de l’expédition de nouveaux produits. Même si la manigance record de o1 n’est pas directement le résultat de cela, elle n’inspire certainement pas confiance. OpenAI dit également que l’Institut de sécurité de l’IA des États-Unis et l’Institut de sécurité du Royaume-Uni ont effectué des évaluations de o1 avant son lancement plus large, une chose que la société s’est récemment engagée à faire pour tous les modèles. Elle a soutenu dans le débat sur le projet de loi californien sur l’IA SB 1047 que les organismes d’État ne devraient pas avoir le pouvoir de fixer des normes de sécurité autour de l’IA, mais que les organismes fédéraux devraient le faire. (Bien sûr, le sort des organismes de régulation de l’IA fédéraux naissants est très incertain.) Derrière les lancements de grands nouveaux modèles d’IA, il y a beaucoup de travail que OpenAI fait en interne pour mesurer la sécurité de ses modèles. Des rapports suggèrent qu’il y a une équipe proportionnellement plus petite de l’entreprise qui fait ce travail de sécurité qu’il n’y en avait auparavant, et l’équipe pourrait recevoir moins de ressources. Cependant, ces conclusions sur la nature trompeuse de o1 peuvent aider à faire valoir pourquoi la sécurité de l’IA et la transparence sont plus pertinentes que jamais.